
😊 About Me
I’m a PhD student at The Chinese University of Hong Kong, supervised by Professor Jiaya, JIA and Professor Bei YU. Before that, I obtained my master degree at AIM3 Lab, Renmin University of China, under the supervision of Professor Qin, JIN. I received my Bachelor’s degree in 2021 from South China University of Technology.
My research interest includes Computer Vision and Multi-modal Large Language Models. Here is my google scholar page.
📝 Main Contributions
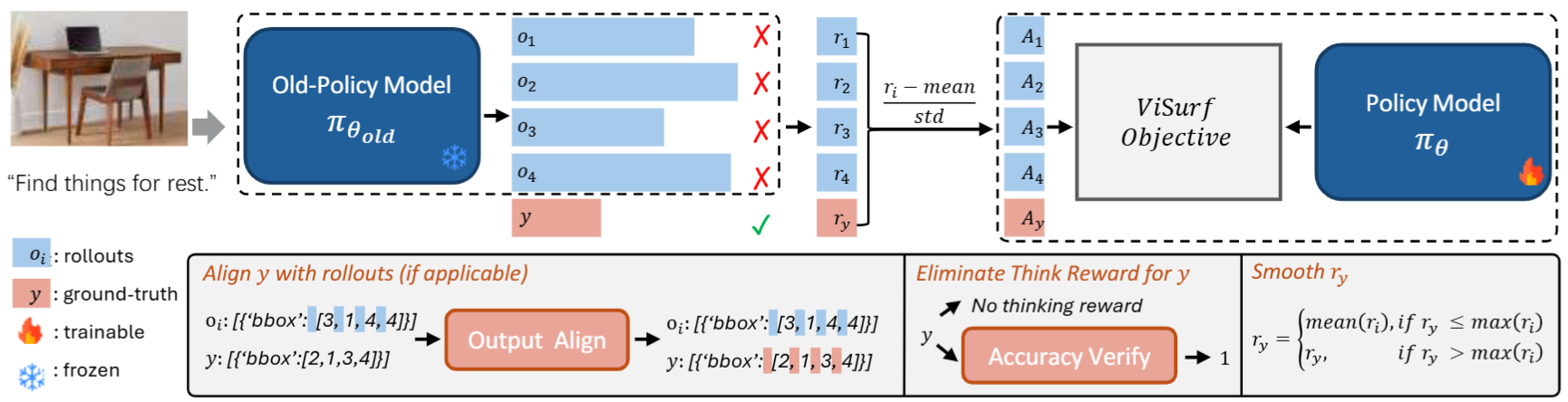
ViSurf: Visual Supervised-and-Reinforcement Fine-Tuning for Large Vision-and-Language Models
Yuqi Liu, Liangyu Chen, Jiazhen Liu, Mingkang Zhu, Zhisheng Zhong, Bei Yu, Jiaya Jia
- ViSurf (Visual Supervised-and-Reinforcement Fine-Tuning) is a unified post-training paradigm that integrates the strengths of both SFT and RLVR within a single stage.

VisionReasoner: Unified Visual Perception and Reasoning via Reinforcement Learning
Yuqi Liu* , Tianyuan Qu* , Zhisheng Zhong, Bohao Peng, Shu Liu, Bei Yu, Jiaya Jia
![[code]](https://img.shields.io/github/stars/dvlab-research/VisionReasoner)
- VisionReasoner is a unified framework for visual perception tasks.
- Through carefully crafted rewards and training strategy, VisionReasoner has strong multi-task capability, addressing diverse visual perception tasks within a shared model.

Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Yuqi Liu , Bohao Peng, Zhisheng Zhong, Zihao Yue, Fanbin Lu, Bei Yu, Jiaya Jia
![[code]](https://img.shields.io/github/stars/dvlab-research/Seg-Zero)
- Seg-Zero exhibits emergent test-time reasoning ability. It generates a reasoning chain before producing the final segmentation mask.
- Seg-Zero is trained exclusively using reinforcement learning, without any explicit supervised reasoning data.
- Compared to supervised fine-tuning, our Seg-Zero achieves superior performance on both in-domain and out-of-domain data.
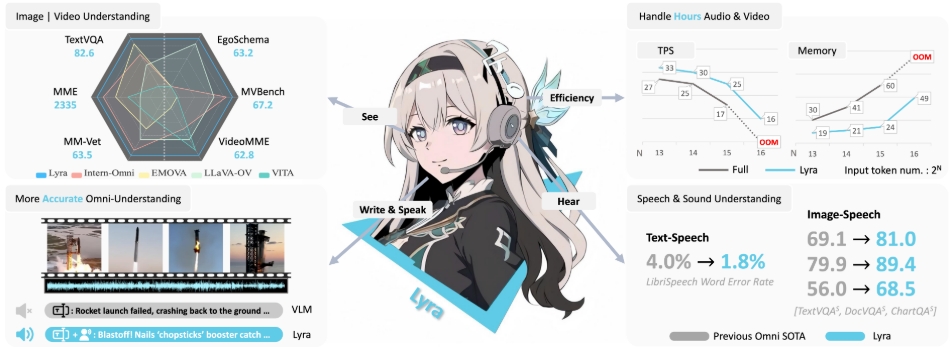
Lyra: An Efficient and Speech-Centric Framework for Omni-Cognition
Zhisheng Zhong*, Chengyao Wang*, Yuqi Liu*, Senqiao Yang,Longxiang Tang, Yuechen Zhang, Jingyao Li, Tianyuan Qu, Yanwei Li, Yukang Chen, Shaozuo Yu, Sitong Wu, Eric Lo, Shu Liu, Jiaya Jia
![[code]](https://img.shields.io/github/stars/dvlab-research/Lyra)
- Stronger performance: Achieve SOTA results across a variety of speech-centric tasks.
- More versatile: Support image, video, speech/long-speech, sound understanding and speech generation.
- More efficient: Less training data, support faster training and inference.
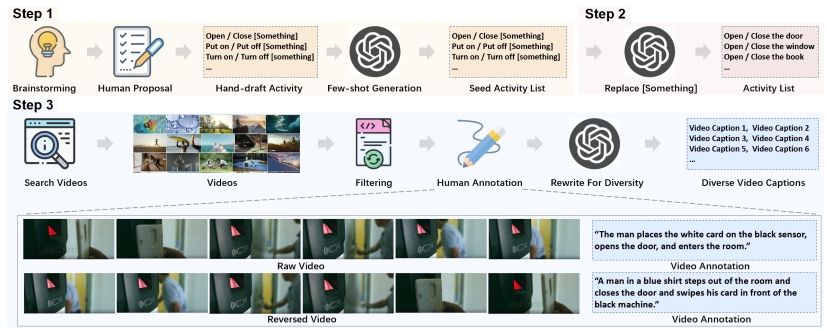
Reversed in Time: A Novel Temporal-Emphasized Benchmark for Cross-Modal Video-Text Retrieval
Yang Du*, Yuqi Liu*, Qin Jin
- A benchmark aims to evaluate temporal understanding of video retrieval models.
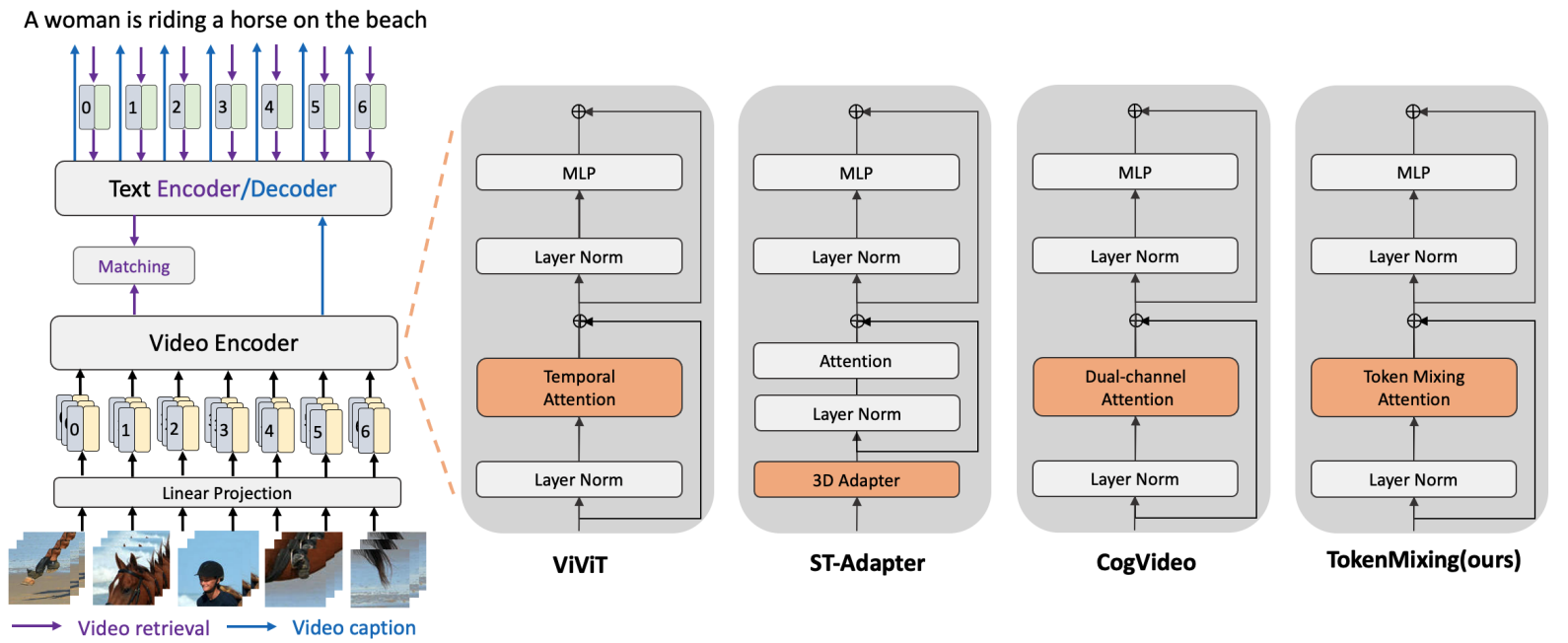
Token Mixing: Parameter-Efficient Transfer Learning from Image-Language to Video-Language
Yuqi Liu, Luhui Xu, Pengfei Xiong, Qin Jin
- We study how to transfer knowledge from image-language model to video-language tasks.
- We have implemented several components proposed by recent works.
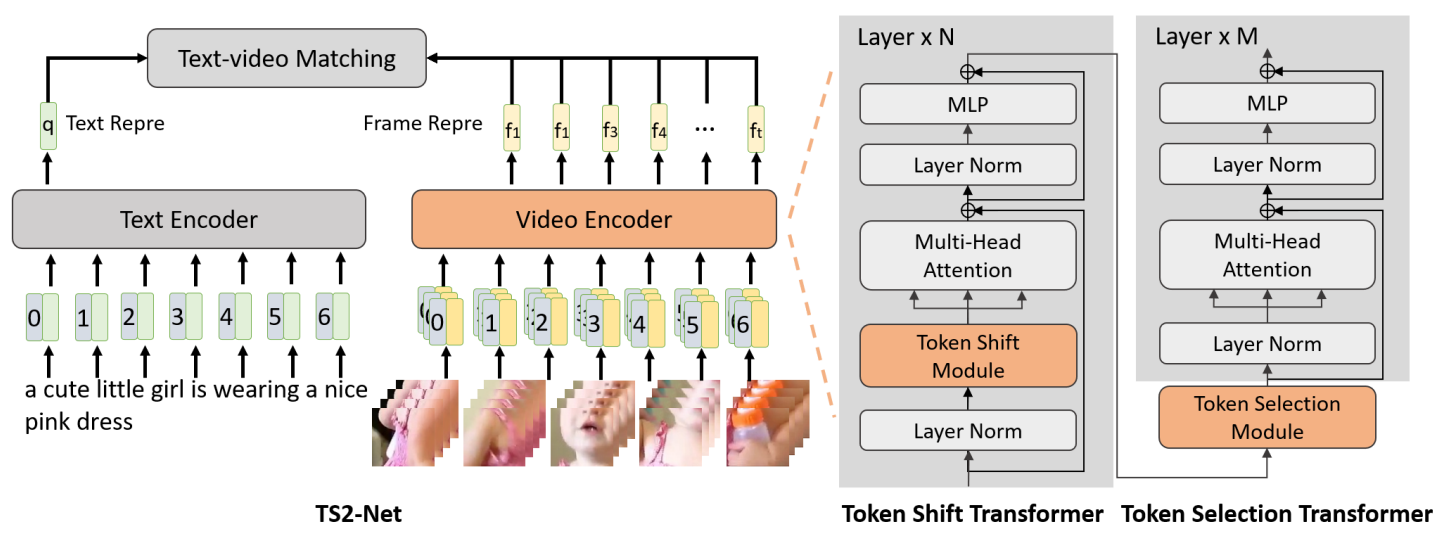
TS2-Net: Token Shift and Selection Transformer for Text-Video Retrieval
Yuqi Liu, Pengfei Xiong, Luhui Xu, Shengming Cao, Qin Jin
- TS2-Net is a text-video retrieval model based on CLIP.
- We propose our token shift transformer and token selection transformer.
📝 Collaborations
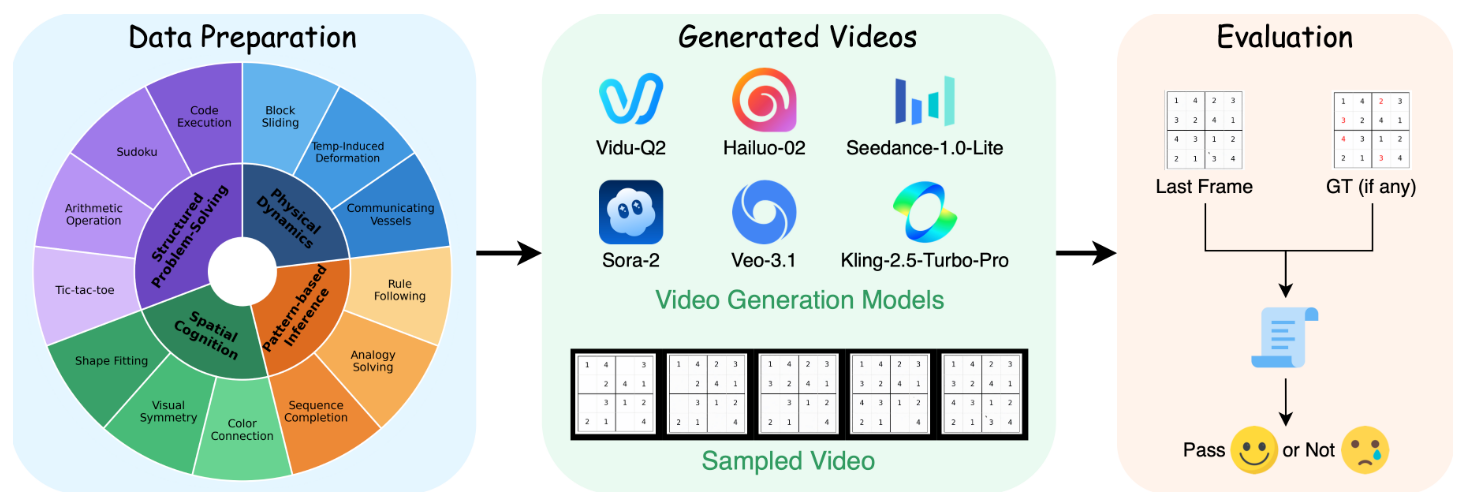
V-ReasonBench: Toward Unified Reasoning Benchmark Suite for Video Generation Models
Yang Luo, Xuanlei Zhao, Baijiong Lin, Lingting Zhu, Liyao Tang, Yuqi Liu, Ying-Cong Chen, Shengju Qian, Xin Wang, Yang You
- V-ReasonBench is a benchmark designed to assess video reasoning across four key dimensions: structured problem-solving, spatial cognition, pattern-based inference, and physical dynamics.

MGM-Omni: Scaling Omni LLMs to Personalized Long-Horizon Speech
Wang Chengyao, Zhong Zhisheng, Peng Bohao, Yang Senqiao, Liu Yuqi, Gui Haokun, Xia Bin, Li Jingyao, Yu Bei, Jia Jiaya
![[code]](https://img.shields.io/github/stars/dvlab-research/MGM-Omni)
- Omni-modality supports: MGM-Omni supports audio, video, image, and text inputs, understands long contexts, and can generate both text and speech outputs, making it a truly versatile multi-modal AI assistant.
- Long-form Speech Understanding: Unlike most existing open-source multi-modal models, which typically fail with inputs longer than 15 minutes, MGM-Omni can handle hour-long speech inputs while delivering superior overall and detailed understanding and performance!
- Long-form Speech Generation: With a treasure trove of training data and smart Chunk-Based Decoding, MGM-Omni can generate over 10 minutes of smooth, natural speech for continuous storytelling.
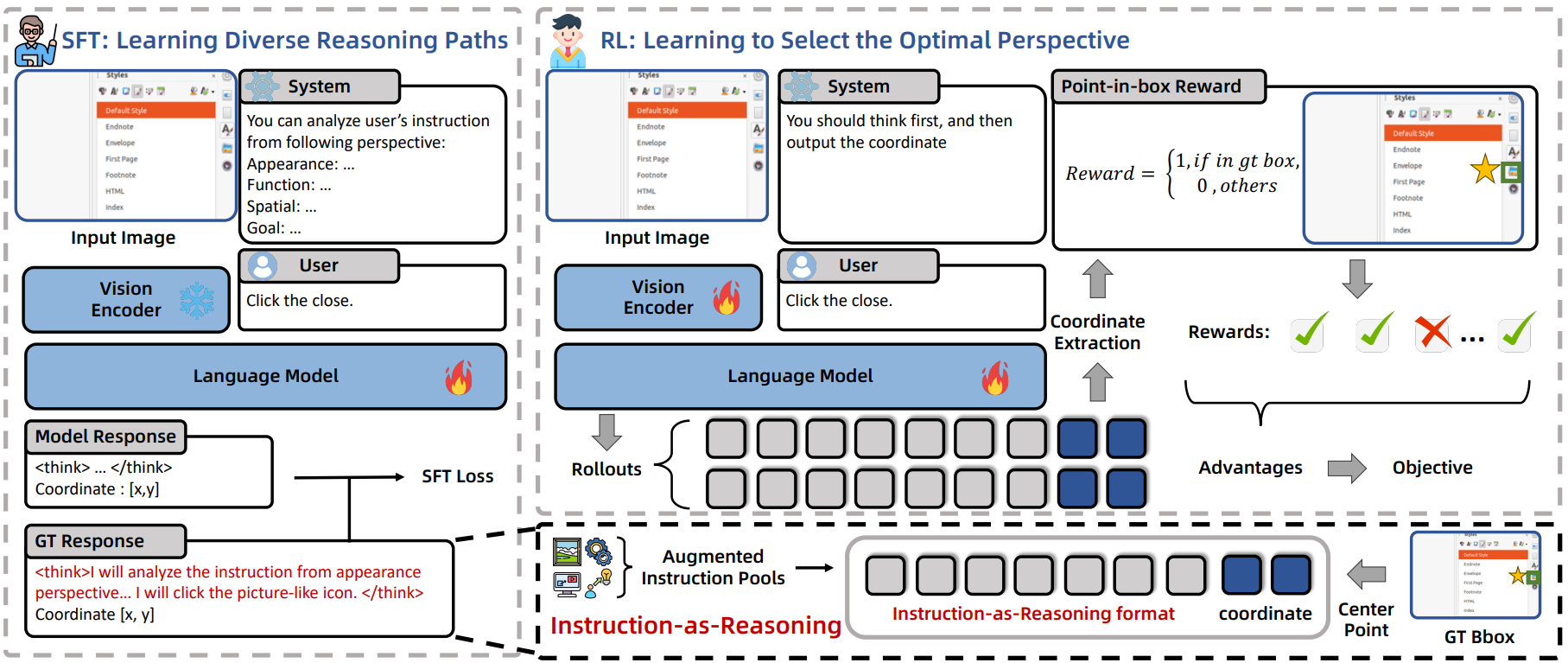
UI-Ins: Enhancing GUI Grounding with Multi-Perspective Instruction-as-Reasoning
Liangyu Chen, Hanzhang Zhou, Chenglin Cai, Jianan Zhang, Panrong Tong, Quyu Kong, Xu Zhang, Chen Liu, Yuqi Liu, Wenxuan Wang, Yue Wang, Qin Jin, Steven HOI
- We introduce the Instruction-as-Reasoning paradigm, treating instructions as dynamic analytical pathways that offer distinct perspectives and enabling the model to select the most effective pathway during reasoning.
- We realize UI-Ins through a SFT+GRPO training framework that first teaches the model to use diverse instruction perspectives as reasoning pathways and then incentivizes it to select the optimal analytical reasoning pathway for any given GUI scenario.
📖 Educations
- 2024.08 - 2028.06 (Expect), Ph.D., Department of Computer Science and Engineering, The Chinese University of Hong Kong.
- 2021.09 - 2024.06, M.Phil., School of Information, Renmin University of China.
- 2017.09 - 2021.06, B.E., School of Software Engineering, South China University of Technology.
📕 Teaching
- 2025 Fall, CSCI1580
- 2025 Spring, ENGG2020
- 2024 Fall, CSCI3170